чёлка — Словообразовательный словарь «Морфема»
What does npm exec do? What is the difference between «npm exec» and «npx»?
What are the building blocks of OWL ontologies?
Learn more about «RDF star», «SPARQL star», «Turtle star», «JSON-LD star», «Linked Data star», and «Semantic Web star».
The Hadamard gate is one of the simplest quantum gates which acts on a single qubit.
Learn more about the bra–ket notation.
Progressive Cactus is an evolution of the Cactus multiple genome alignment protocol that uses the progressive alignment strategy.
The Human Genome Project is an ambitious project which is still underway.
What are SVMs (support vector machines)?
Find out more in Eckher’s article about TensorFlow.js and linear regression.
On the importance of centralised metadata registries at companies like Uber.
Facebook’s Nemo is a new custom-built platform for internal data discovery. Learn more about Facebook’s Nemo.
Learn more about Facebook’s Nemo.
What is Data Commons (datacommons.org)? Read Eckher’s introduction to Data Commons (datacommons.org) to learn more about the open knowledge graph built from thousands of public datasets.
Learn more about how Bayer uses semantic web technologies for corporate asset management and why it enables the FAIR data in the corporate environment.
An introduction to WikiPathways by Eckher is an overview of the collaboratively edited structured biological pathway database that discusses the history of the project, applications of the open dataset, and ways to access the data programmatically.
Eckher’s article about question answering explains how question answering helps extract information from unstructured data and why it will become a go-to NLP technology for the enterprise.
Read more about how document understanding AI works, what its industry use cases are, and which cloud providers offer this technology as a service.
Lexemes are Wikidata’s new type of entity used for storing lexicographical information. The article explains the structure of Wikidata lexemes and ways to access the data, and discusses the applications of the linked lexicographical dataset.
The guide to exploring linked COVID-19 datasets describes the existing RDF data sources and ways to query them using SPARQL. Such linked data sources are easy to interrogate and augment with external data, enabling more comprehensive analysis of the pandemic both in New Zealand and internationally.
The introduction to the Gene Ontology graph published by Eckher outlines the structure of the GO RDF model and shows how the GO graph can be queried using SPARQL.
The overview of the Nobel Prize dataset published by Eckher demonstrates the power of Linked Data and demonstrates how linked datasets can be queried using SPARQL. Use SPARQL federation to combine the Nobel Prize dataset with DBPedia.
Learn why federated queries are an incredibly useful feature of SPARQL.
What are the best online Arabic dictionaries?
How to pronounce numbers in Arabic?
List of months in Maori.
Days of the week in Maori.
The list of country names in Tongan.
The list of IPA symbols.
What are the named entities?
What is computational linguistics?
Learn how to use the built-in React hooks.
Learn how to use language codes in HTML.
Learn about SSML.
Browse the list of useful UX resources from Google.
Where to find the emoji SVG sources?.
What is Wikidata?
What’s the correct markup for multilingual websites?
How to use custom JSX/HTML attributes in TypeScript?
Learn more about event-driven architecture.
Where to find the list of all emojis?
How to embed YouTube into Markdown?
What is the Google Knowledge Graph?
Learn SPARQL.
Explore the list of coronavirus (COVID-19) resources for bioinformaticians and data science researchers.
Sequence logos visualize protein and nucleic acid motifs and patterns identified through multiple sequence alignment. They are commonly used widely to represent transcription factor binding sites and other conserved DNA and RNA sequences. Protein sequence logos are also useful for illustrating various biological properties of proteins. Create a sequence logo with Sequence Logo. Paste your multiple sequence alignment and the sequence logo is generated automatically. Use the sequence logo maker to easily create vector sequence logo graphs. Please refer to the Sequence Logo manual for the sequence logo parameters and configuration. Sequence Logo supports multiple color schemes and download formats.
Sequence Logo is a web-based sequence logo generator. Sequence Logo generates sequence logo diagrams for proteins and nucleic acids. Sequence logos represent patterns found within multiple sequence alignments. They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
They consist of stacks of letters, each representing a position in the sequence alignment. Sequence Logo analyzes the sequence data inside the user’s web browser and does not store or transmit the alignment data via servers.
Te Reo Maps is an online interactive Maori mapping service. All labels in Te Reo Maps are in Maori, making it the first interactive Maori map. Te Reo Maps is the world map, with all countries and territories translated into Maori. Please refer to the list of countries in Maori for the Maori translations of country names. The list includes all UN members and sovereign territories.
Phonetically is a web-based text-to-IPA transformer. Phonetically uses machine learning to predict the pronunciation of English words and transcribes them using IPA.
Punycode.org is a tool for converting Unicode-based internationalized domain names to ASCII-based Punycode encodings. Use punycode.org to quickly convert Unicode to Punycode and vice versa. Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
Internationalized domains names are a new web standard that allows using non-ASCII characters in web domain names.
My Sequences is an online platform for storing and analyzing personal sequence data. My Sequences allows you to upload your genome sequences and discover insights and patterns in your own DNA.
Словообразовательный словарь «Морфема» дает представление о морфемной структуре слов русского языка и слов современной лексики. Для словообразовательного анализа представлены наиболее употребительные слова современного русского языка, их производные и словоформы. Словарь предназначен школьникам, студентам и преподавателям. Статья разбора слова «сладкоежка» по составу показывает, что это слово имеет два корня, соединительную гласную, суффикс и окончание. На странице также приведены слова, содержащие те же морфемы. Словарь «Морфема» включает в себя не только те слова, состав которых анализируется в процессе изучения предмета, но и множество других слов современного русского языка. Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Словарь адресован всем, кто хочет лучше понять структуру русского языка.
Разбор слова «кормушка» по составу.
Разбор слова «светить» по составу.
Разбор слова «сбоку» по составу.
Разбор слова «шиповник» по составу.
Разбор слова «народ» по составу.
Разбор слова «впервые» по составу.
Разбор слова «свежесть» по составу.
Разбор слова «издалека» по составу.
Разбор слова «лесной» по составу.
Морфологический разбор слова «челка»
Часть речи: Существительное
ЧЕЛКА — неодушевленное
Начальная форма слова: «ЧЕЛКА»
| Слово | Морфологические признаки |
|---|---|
| ЧЕЛКА |
|
Все формы слова ЧЕЛКА
ЧЕЛКА, ЧЕЛКИ, ЧЕЛКЕ, ЧЕЛКУ, ЧЕЛКОЙ, ЧЕЛКОЮ, ЧЕЛОК, ЧЕЛКАМ, ЧЕЛКАМИ, ЧЕЛКАХ
Разбор слова по составу челка
| Основа слова | чёлк |
|---|---|
| Корень | чёлк |
| Окончание | а |
Разбор слова в тексте или предложении
Если вы хотите разобрать слово «ЧЕЛКА» в конкретном предложении или тексте, то лучше использовать
морфологический разбор текста.
Примеры предложений со словом «челка»
1
В школе ее все так и звали – Челка и Челка.
День свалившихся с луны, Наташа Труш2
Не все, только челка, но эта челка была похожа на розовую сахарную вату.
Собака в подарок, Сьюзан Петик, 2017г.3
Мама смотрит на меня сверху вниз, густая челка лезет в глаза, над челкой смешным узлом топорщится моя синяя косынка.
4
Девушка мастерски сдула чёлку со лба, после чего чёлка, разумеется, вернулась на прежнее место.
Троечник, Валерий Вайнин5
Лене моя челка нравится, она крутится перед зеркалом, прикладывая кончик косы ко лбу, имитируя челку.
Розовый дом на холме, Людмила ДорогининаНайти еще примеры предложений со словом ЧЕЛКА
фонетический разбор, примеры предложений, синонимы, связанные слова
классике
— куда девается
ощущение — кремдесерт
в глазах Лошади
— кружится воздух
Arrigo aminos
— в фонде количества — бережок изогнул камышовую гривку
Именно после того сна она впервые ухитрилась накрутить свою гривку, а потом долго смотрелась в воду тихого заливчика.

Девочка потрогала «Сивку-Бурку», погладила ее мягонькую гривку, заглянула в умные карие глазки и уже хотела уходить, но тут лошадка тихо сказала, глядя
Где таилась эта сиреневая тучка Обо что запнулась, какая веточка берёзовая продырявила её пушистую гривку Ведёрко, которое плыло на спинке тучки, опрокинулось
«Зинка далеко», — почесал гривастую гривку, поднял крошечные глазёнки кверху и остолбенел!
Она глубоко вздохнула, запрокинула свою чудесную гривку и сказала:
— Не… Не найду я дома сразу двух подружек, изревнуются они…
кто
Может тигр полосатый, сердитый очень и усатый
Чёрная чёлка и хвостик метёлка, тигрёнок сметает иголки от ёлки,
Чёрную чёлку назад убирает, чёрную гривку
Лицо девушки было скрыто журналом, так что я мог разглядеть только лоб и гривку рыжих волос, красивыми волнами спадающих на плечи.

действительно лось, а не селезень, она ловко стала работать дальше и вскоре обрила всего лося целиком, только кисточку на кончике хвоста оставила да гривку
— поцеловала ее в носик другая, вытирая ей слезинки и поправляя заботливо гривку.
Дрожащие серые пальчики скребли розовый носик и гладили искусственную гривку.
— Я люблю тебя! Я люблю тебя!
Кабуто прочувствовал это и посмотрел ему вслед, не обращая внимания на то, как ветер треплет ему коротенькую черную гривку, с длинной челкой, искристую
Крысёнок гривку почесал,
Глазенки к небесам поднял…
И удивлён нимало был…
Дым шёл от двух резиновых мудил!
А мне есть в чем проявить недовольство, за что потрепать вас по гривку и погладить против шерстки. Но есть и за что благодарить и лелеять.
А ослик пускается в такой галоп, что брат и сестра с трудом держатся за короткую рыжую Иашкину гривку.

А ослик пускается в такой галоп, что Игорь и Вероника еле-еле могут удержаться за короткую рыжую Иашкину гривку.
Солнце поднималось, когда наткнулась на гривку, усыпанную брусникой. Спелая, почти чёрная ягода насытила до оскомины. Клонило в сон.
Перебрался через гривку, пересек увядший от засухи молодняк и вышел к бочагу, на дне которого, в грязи ковырялась пацанва.
Поскольку условное изображение львиного пардуса (гепарда, имеющего маленькую гривку) и льва в Европе отличались только поворотом головы (на гербах лев
Тянулась всем своим телом к хозяину, когда он гладил ее под шеей, расчесывал гривку между рогами. Но как-то вечером мы услышали стон.
самые модные образы – BestBarber
Челка в сфере парикмахерского искусства – эффективный прием, когда необходимо замаскировать недостатки внешности, а также подчеркнуть достоинства. Если мужчина решился кардинально изменить образ, можно сделать это с помощью смены прически. Какие мужские прически с челкой сейчас в тренде и что рекомендуют современные барберы – узнаете из нашей статьи.
Если мужчина решился кардинально изменить образ, можно сделать это с помощью смены прически. Какие мужские прически с челкой сейчас в тренде и что рекомендуют современные барберы – узнаете из нашей статьи.
Среди причесок с челкой немало ярких смелых решений, которые смогут воодушевить мужчин на поход в барбершоп. Правильно выбранная и хорошо уложенная челка позволяет выгодно дополнить образ мужчины. Какие сейчас в моде мужские стрижки с челкой – читайте далее.
Стрижки для мужчин: как выбрать правильную челку?
С помощью челки можно выделить красивые черты лица мужчины. Сегодня барберы предлагают стильные парикмахерские решения с челкой, которые подойдут многим мужчинам.
- Небрежность уже давно в моде. Отросшая челка с длинными прядями – хит сезона 2020. Первоначально кажется, что парень запусти себя и давно не был у своего мастера. Но это не так. Мужчина с небрежной прической следит за новыми тенденциями барбер-индустрии и следует актуальным веяниям.

- Мужская прическа с длинной челкой на бок – прекрасное сочетание. Особенно круто выглядит длинная челка со стрижками «андеркат» или «помпадур». Если через какой-то период пряди надоедают, челку можно убрать заколкой или завязать ее в пучок. Челку на бок часто комбинируют с различными стрижками. Асимметрия – отличный метод скорректировать черты лица, скрыть неправильную форму головы. Чтобы укладка длинной челки не занимала много времени, необходимо использовать специальные профессиональные косметические средства. Среди разнообразия спреев для стайлинга волос, каждый сможет подобрать для себя наиболее подходящий по структуре и составу. Если же возникают сложности с выбором средств для укладки волос и челки – можно обратиться за консультацией к мастерам барбершопов.
- Мужская стрижка с челкой неординарно смотрится и на кучерявых волосах. Кудряшки – гордость их обладателя. Все, что необходимо – отрастить пряди средней длины, а челку направить вверх. В уходе за длинными волнистыми прядями мужчинам помогут пенка или мусс для укладки. С профессиональными средствами укладка кудрявой челки станет проще и быстрее. Если необходимо принимать участие в торжественных мероприятиях, надо выглядеть соответствующе. Для таких случаев отлично подходит стрижка с кудрявыми волосами, которые зачесываются назад. Длина прядей должны быть выше средней, тогда волосы будут смотреться элегантно. В сочетании с черным смокингом мужчина будет выглядеть неотразимо.
- Челка в короткой мужской стрижке создает стильный и креативный образ. Стрижка «андеркат» прекрасно сочетается с челкой разной длины и подходит мужчинам с любым типом лица. Любители коротких стрижек могут не изменять своим привычкам – такой стиль сейчас в тренде.
- Наиболее распространенная мужская прическа с челкой – это «помпадур». Она дает возможность сбрить волосы в височной зоне и на затылке, но предполагает наличие челки. Если ваши волосы непослушные и челка не лежит как надо, — попробуйте применить мужской лак для укладки, который позволит вам зафиксировать челку в нужном направлении. Максимальную фиксацию челки может также обеспечить гель для волос.
- Классика для тех, кто любит сдержанность в мужском образе. Мужчины, предпочитающие консервативный стиль, могут отдать предпочтение прическе в классическом стиле, которая предполагает стандартную небольшую челку. Представители сильного пола со стандартными стрижками всегда выглядят ухоженно и обаятельно.
- Что делать бородачам? Когда есть борода, стрижку с челкой легко сочетать с внешним видом. В этом случае как раз можно поэкспериментировать с челкой – уложить ее на бок или зачесать назад. В комбинации с растительностью на лице, волосы кажутся гуще, а образ мужчины – законченным.

 В уходе за длинными волнистыми прядями мужчинам помогут пенка или мусс для укладки. С профессиональными средствами укладка кудрявой челки станет проще и быстрее. Если необходимо принимать участие в торжественных мероприятиях, надо выглядеть соответствующе. Для таких случаев отлично подходит стрижка с кудрявыми волосами, которые зачесываются назад. Длина прядей должны быть выше средней, тогда волосы будут смотреться элегантно. В сочетании с черным смокингом мужчина будет выглядеть неотразимо.
В уходе за длинными волнистыми прядями мужчинам помогут пенка или мусс для укладки. С профессиональными средствами укладка кудрявой челки станет проще и быстрее. Если необходимо принимать участие в торжественных мероприятиях, надо выглядеть соответствующе. Для таких случаев отлично подходит стрижка с кудрявыми волосами, которые зачесываются назад. Длина прядей должны быть выше средней, тогда волосы будут смотреться элегантно. В сочетании с черным смокингом мужчина будет выглядеть неотразимо. Максимальную фиксацию челки может также обеспечить гель для волос.
Максимальную фиксацию челки может также обеспечить гель для волос.Мужская челка: средней длины, косая или в виде длинных прядей – кому какая подходит
Челка – важная деталь, дополняющая образ мужчины, поэтому не стоит спешить с ее выбором. Сначала просмотрите все возможные варианты в интернете, обсудите новый образ с вашим мастером в барбершопе, выслушайте рекомендации специалиста касательно того, какая интерпретация стрижки с челкой подойдет именно вашему типу лица – и только после этого приступайте к выбору.
Объемная челка визуально удлинит овал лица, если требуется. Как говорят барберы, особенность лица мужчины реально скорректировать грамотно подобранной челкой.
Представители сильного пола, которые недовольны своей линией роста волос, могут попробовать изменить стиль челки – уложить ее вверх или вовсе зачесать назад, тем самым приоткрыв зону лба и бровей.
Челка, требующая длину волос выше средней, имеет немало плюсов. Она прекрасно комбинирует со стрижками, где волосы в височной части очень коротко подстрижены. В таких образах челку можно уложить в разные стороны, как удобно ее владельцу.
Длинную челку удобно зачесать на бок, придав ей эффект гладкой укладки с помощью использования геля.
Косая челка в сочетании с короткой стрижкой – классика жанра. Подойдет как молодым парням, так и для мужчин более зрелого возраста. Если волосы начинают завиваться после очередного мытья и вы не знаете, как уложить косую челку, попробуйте добавить немного воска – ваша челка будет надежно зафиксирована.:max_bytes(150000):strip_icc()/Kendellfringe-a6dc10bb9c4c40389a06c29e883b49f9.jpg)
Не стоит забывать, что челка должна гармонировать с прической и выгодно дополнять образ. Прекрасно, когда челка – это естественное продолжение стрижки.
Каждой стрижке — своя челка
Мужчины, которые выбрали вариант прически «под горшок», могут носить густую челку. Однако, важно предварительно выпрямить пряди, — тогда стрижка будет смотреться эффектно.
Креативным парням с «ирокезом» на голове не нужно экспериментировать с челкой – достаточно уложить ее ровно по направлению стрижки.
Стильное решение – укоротить волосы в височной области и затылке, а сверху отрастить более длинные пряди, добавив «творческий беспорядок». Такая прическа была популярна несколько лет назад среди звезд кино, но и сейчас она держится в тренде.
Обладателям седых волос уважаемого возраста не стоит расстраиваться. Эту особенность также можно выгодно подчеркнуть. Барберы рекомендуют выбрать мужскую прическу с челкой вверх – и восторженные взгляды представителей прекрасного пола вам обеспечены.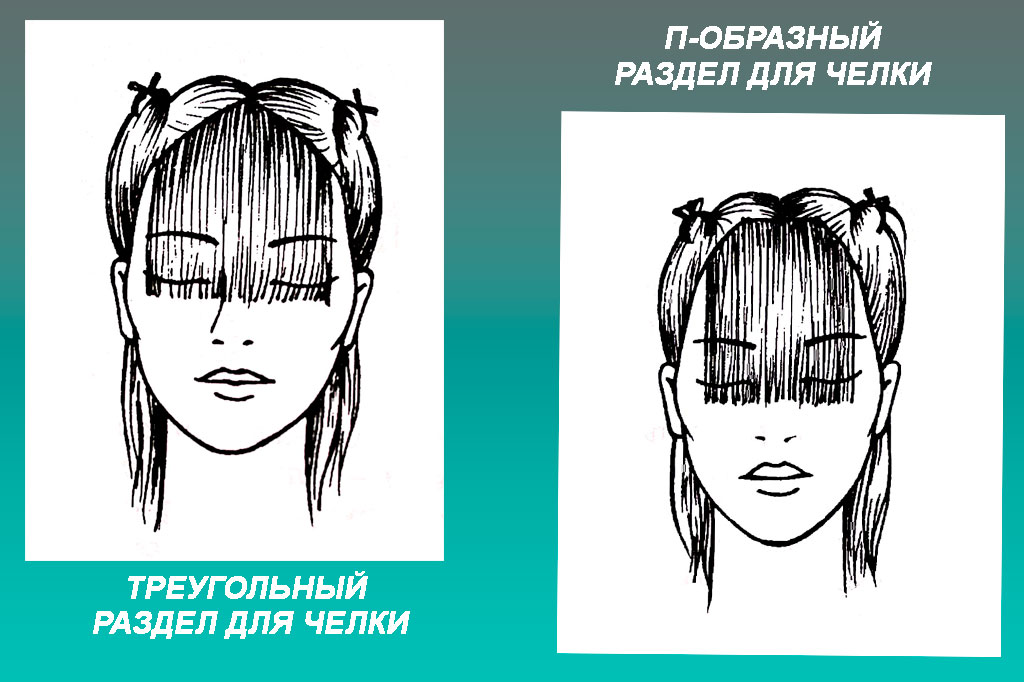 Стрижка предполагает отрастить челку около 5 см, а по бокам и на затылке волосы должны быть максимально короткими. Такая прическа дает возможность смело приоткрыть лоб, и лицо всегда будет выглядеть молодо и свежо.
Стрижка предполагает отрастить челку около 5 см, а по бокам и на затылке волосы должны быть максимально короткими. Такая прическа дает возможность смело приоткрыть лоб, и лицо всегда будет выглядеть молодо и свежо.
Не перестает выходить из моды стиль «ретро». Длинные пряди вверху, которые зачесаны назад и выбритыми висками. Этот вид прически был создан стилистами давно, но он не выходит из моды. Идеально выбритые бока, а вверху челка стоит дыбом – такой прической вы сможете сразить многих девушек. Стильный оригинальный образ, который подойдет парням от 15 и до 30 лет.
Учитывая, что вариаций стрижек с челкой действительно много, не удивительно, что мужские прически с челкой находятся на пике моды. С каждым днем барберы создают все новые решения, которые приходятся по душе мужскому населению. Если сложно самостоятельно подобрать идеальную стрижку с челкой, которая бы подходила именно под вашу длину волос, можно обратиться к специалистам. В современном барбершопе с удовольствием проконсультируют вас, подробно расскажут о том, какие сейчас актуальные мужские стрижки с челкой и подберут подходящий вариант для вас. Кроме этого, стрижка у специалиста будет отличаться простотой укладки челки и идеальным видом даже при естественном просушивании без использования средств для фиксации прически. Не бойтесь экспериментировать с прическами – новый образ, созданный опытными барберами, приятно удивит вас и поможет выглядеть современно и стильно.
Кроме этого, стрижка у специалиста будет отличаться простотой укладки челки и идеальным видом даже при естественном просушивании без использования средств для фиксации прически. Не бойтесь экспериментировать с прическами – новый образ, созданный опытными барберами, приятно удивит вас и поможет выглядеть современно и стильно.
70-е, кудри и перья: как носить челку в 2020 году
Челка — быстрый способ немного изменить внешность, не делая при этом принципиально новую стрижку или сложное окрашивание. Рассказываем, какие челки будут актуальны в 2020 году и как их носить.
Короткая челка
© Getty Images Микрочелка всегда поджидает где-то поблизости — мы видим ее на Неделях моды, затем на красных дорожках, в ленте Instagram и в кино. У такой челки довольно много вариаций исполнения — она может быть запредельно короткой, рваной или наоборот — очень густой. Сути это нисколько не меняет — baby bangs (от английского — детская челка) не теряет своей актуальности уже долгие годы и продолжит держать планку в 2020 году.
Сути это нисколько не меняет — baby bangs (от английского — детская челка) не теряет своей актуальности уже долгие годы и продолжит держать планку в 2020 году.
Кудрявая челка
© Getty ImagesВариант для обладательниц вьющихся волос и тех, кто готов тратить время на завивку — кудрявая челка. Это могут быть крупные локоны на весь лоб или несколько романтичных скрученных прядей, которые будто случайно выбились из прически.
Челка-треугольник
© Instagram Англоговорящим пользователям Сети такая челка больше известна под названием V-bangs, потому что действительно напоминает букву V. Больше всего подобную вариацию полюбили готы и поклонники сайкобилли, но носить ее может кто угодно (даже если ни разу в жизни не слышал The Cure). К созданию V-bangs подходят решительно: угол делают очень острым, а волосы на лбу часто выбривают для создания идеальной формы челки. Нарушить эти правила тоже можно, сделав V-образную форму менее выраженной.
Нарушить эти правила тоже можно, сделав V-образную форму менее выраженной.
Перья
© Legion-Media
© Legion-Media
© Legion-Media
© Legion-Media
© Legion-Media
Перья давно перестали быть частью бурлеска и вошли в повседневные образы в виде украшений, деталей на одежде и аксессуаров. На осеннем показе Dries Van Noten предложили еще вариант использования перьев — вплетать их в челки. Конечно, не многие рискнут ходить в таком виде на работу, но для вечеринок очень подходит.
Челка из 70-х
© Instagram Одним словом — классика! Длинную, не слишком густую челку успели примерить очень многие, а она и не думает терять актуальности. У этих челок есть прочно утвердившийся бэкграунд: считается, что их носят только истинные француженки (вспомните юную Брижит Бардо или англо-французскую актрису Джейн Биркин). Но в целом, нет нужды любить береты с красной помадой и поддерживать этот миф, чтобы носить легендарную челку.
У этих челок есть прочно утвердившийся бэкграунд: считается, что их носят только истинные француженки (вспомните юную Брижит Бардо или англо-французскую актрису Джейн Биркин). Но в целом, нет нужды любить береты с красной помадой и поддерживать этот миф, чтобы носить легендарную челку.
| Перепись 1701, РГАДА 1209-1-6446, 1698—1701 г. | ||||||||||
| 3340036 | деревня Чолки речки | Казанское царство, Казанский уезд | Алатская дорога, Кукарская слобода | — | — | — | 132об—141 | |||
| Перепись 1710, РГАДА 350-1-135, 1710 г. | ||||||||||
| 3020017 | в деревне Чолке | Казанская губерния | Алатская дорога, дворцовая Кукарская слобода с деревнями | дворцовые крестьяне | 31 | ♂ 138 ♀ 137 | 45об—49об | |||
Ландратская перепись, РГАДА 350-1-138, 1716 г. | ||||||||||
| 3040019 | в деревне Челке | Казанская губерния | Алатская дорога, Кукарская слобода, [Ильинская треть] | дворцовые крестьяне | 20 | — | 93об—99 | |||
| 1‑я ревизия (1719‑21), РГАДА 350-2-1080, 1719—1721 г. | ||||||||||
| 3170165 | в деревне Чолках | Казанская губерния | Алатская дорога, у дворцовой Кукарской слободы | [дворцовые крестьяне] | — | ♂ 17 | 178 | |||
| 3170819 | деревни Челки | Казанская губерния | Алатская дорога, у дворцовой Кукарской слободы | — | — | — | 299—300об | |||
| 1‑я ревизия (1722‑27), РГАДА 350-2-1104, 1721—1725 г. | ||||||||||
| 3220049 | в деревне Чолках | Казанская губерния | Алатская дорога, у дворцовой Кукарской слободы | — | — | ♂ 17 | 66 | |||
1‑я ревизия (1722‑27), РГАДА 350-2-1115, 1722—1723 г. | ||||||||||
| 3230012 | деревни Чолки | Казанская губерния | Алатская дорога, у дворцовой Кукарской слободы | — | — | — | 128—137об | |||
| 2‑я ревизия, РГАДА 350-2-1135, 1748 г. | ||||||||||
| 2850021 | деревня Чолка (Челка) | Казанская губерния, Казанская провинция, Казанский уезд | Алатская дорога, Кукарская дворцовая волость | дворцовые крестьяне | — | ♂ 196 | 6293—6488 | 106об—115 | ||
| 2‑я ревизия, РГАДА 350-2-1149, 1748 г. | ||||||||||
| 2880173 | деревни Чолки | Казанская губерния, Казанская провинция, Казанский уезд | Алатская дорога, Кукарская дворцовая волость | из дворцовых крестьян | — | — | 179—180 | 26—26об | ||
2‑я ревизия. Выбывшие, РГАДА 350-2-1151, 1748 г. Выбывшие, РГАДА 350-2-1151, 1748 г. | ||||||||||
| 2890016 | в деревне Чолке | Казанская губерния, Казанская провинция, Казанский уезд | Алатская дорога, Кукарская дворцовая волость | — | — | ♂ 94 | 5468—5561 | 39—42 | ||
| 3‑я ревизия, РГАДА 350-2-1167, 1762—1764 г. | ||||||||||
| 2540028 | В деревне Чолке | Казанская губерния, Казанская провинция, Казанский уезд | Алатская дорога, Кукарская дворцовая волость | дворцовые крестьяне | — | ♂ 189 ♀ 299 | 273—296 об. | |||
| Примечание: 3 февраля 1764 | ||||||||||
Мой личный опыт наращивания челки
Я как любая девушка очень подвержена всяким «хотелкам». Вот в какой то из дней, листая по дороге на работу ленту одной социальной сети, я решила, что мне нужно нарастить челку. Работы мастера запали мне в душу. Смотрелось все на других просто супер. От натуральных волос не отличишь.
Работы мастера запали мне в душу. Смотрелось все на других просто супер. От натуральных волос не отличишь. После звонка мастеру я столкнулась с первой проблемой — рыжих прядок нет, НО есть натурального цвета и их можно покрасить. Меня это не остановило, ведь мне очень хотелось стать обладательницей стильного каре а-ля Бузова.)))
Технология наращивания заключается в следующем: заранее заготавливаются пряди, обработанные по краю смоляным составом. Затем, при помощи нагревательного прибора (горячие ножницы, щипцы), смола на прядках растапливается до нужной температуры. При этом смоляная дорожка превращается в небольшие росинки, как бы капсулы. И пока смола не затвердела, нужно успеть соединить пряди.
В среднем наращивание челки занимает от часа до двух.
Как происходит процесс наращивания: волосы разделяются на пробор, который остается фиксированным на все время носки наращенных прядей. И уже под верхние волосы пробора идет наращивание. Отдельно надо сказать, что мастер мне попался такой же экспериментатор как и я.
 Потому что когда я пришла на наращивание, меня уже ждали покрашенные пряди, которые отлично совпали с моими.
Потому что когда я пришла на наращивание, меня уже ждали покрашенные пряди, которые отлично совпали с моими. На этом фото видно как одна прядка убежала из общей массы. Сверху капсулы не видно и многие коллеги решили, что я просто зачесала волосы по другому.
А теперь лично о моих ощущениях от этого эксперимента. В первые дни мне было жутко не удобно и дискомфортно, потому что дома я привыкла убирать волосы в высокий хвост. С нарощенными прядями это было проблематично, потому что их видно, место крепления тянет и больно кожу головы. Волосы нужно не просто мыть и ухаживать, но и обязательно укладывать утюжками, иначе разница между своими и нарощенными прядями становится заметной. И, конечно, однообразие прически. Лично для меня эксперимент закончился через месяц. Это был интересный опыт, но продолжения я уже не хотела. Тем более с челкой, как мне кажется, я выгляжу моложе)))
Всем удачных экспериментов!!!
Bangs, Crackles & Whistles — Сложный процент
Нажмите для увеличения С приближением 5 ноября отдаленные сообщения о ранних фейерверках уже можно услышать по вечерам здесь, в Великобритании. Обсуждение химического состава фейерверков обычно сосредоточено на соединениях, используемых для создания цветовой гаммы, но за звуками, которые они издают, также стоит много химии. Здесь мы кратко рассмотрим некоторые способы, которыми химики-пиротехники придают фейерверкам характерные хлопки и визги.
Обсуждение химического состава фейерверков обычно сосредоточено на соединениях, используемых для создания цветовой гаммы, но за звуками, которые они издают, также стоит много химии. Здесь мы кратко рассмотрим некоторые способы, которыми химики-пиротехники придают фейерверкам характерные хлопки и визги.
Очевидное место для начала — это взрывы фейерверков, когда они взрываются всплесками цвета. Их можно производить просто из уплотненного пороха, который при подходящем ограничении может дать достойный результат. Однако чаще всего используется воспламенение определенной взрывоопасной смеси. Эта смесь содержит три основных компонента: окислитель (например, хлорат калия), серу (или трисульфид сурьмы) и металлические детали (обычно алюминий).
Эти композиции известны как «flash and sound» по вполне понятным причинам.Окислитель обеспечивает кислород, когда он разлагается, а металл действует как топливо, вызывая быструю взрывную реакцию. Эти композиции особенно опасны; те, которые сделаны с хлоратом калия в качестве окислителя, имеют низкие температуры воспламенения (всего 200 ° C), и даже те, которые сделаны с перхлоратом калия, опасны. Таким образом, смесь обычно создается удаленно.
Таким образом, смесь обычно создается удаленно.
Другой распространенный звуковой эффект в фейерверках — это шипящий треск. В этих фейерверках используется немного другая композиция для достижения эффекта.Первоначально тетроксид свинца был одним из соединений, используемых в этой композиции, но из-за токсичности соединений свинца в настоящее время чаще используются такие соединения, как триоксид висмута и субкарбонат висмута. Эти соединения смешаны с магнием (сплав алюминия и магния).
Затем композиция формируется в гранулы, и быстрое сгорание этих гранул приводит к эффекту потрескивания. Было высказано предположение, что магний в сплаве сначала сгорает в кислороде, выделяемом при разложении оксидов свинца или висмута, а затем алюминий в сплаве вступает в реакцию с оставшимся оксидом свинца / висмута, восстанавливая его до металлического свинца или висмута.Смесь в пиротехнической промышленности обычно называют «драконьими яйцами».
Наконец, один из наиболее распространенных звуковых эффектов, сопровождающих фейерверки, — это визжащие свистки, когда они поднимаются в небо. Это следствие использования некоторых органических соединений. Могут использоваться различные ароматические органические соединения; Ранее использовались соли очень чувствительной к удару пикриновой кислоты, но теперь чаще используются соли галловой кислоты, салициловой кислоты и бензойной кислоты.
Это следствие использования некоторых органических соединений. Могут использоваться различные ароматические органические соединения; Ранее использовались соли очень чувствительной к удару пикриновой кислоты, но теперь чаще используются соли галловой кислоты, салициловой кислоты и бензойной кислоты.
Эти органические соединения смешиваются с окислителями, а затем плотно упаковываются в фейерверк.Когда они горят, ароматические соединения производят небольшие взрывы, которые вызывают изменение давления газа, выбрасываемого горящей смесью. Это создает стоячую волну в трубке, и по мере увеличения расстояния между концом трубки и горящей смесью увеличивается и длина волны, создавая характерный нисходящий свистящий звук.
Изображение в этой статье находится под лицензией Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.См. Рекомендации по использованию содержания сайта.
Ссылки и дополнительная литература
Химический состав фейерверков • Sustainablog
Часть 2: Представляют ли фейерверки значительную опасность для окружающей среды?
Питтсбург, Пенсильвания . Место, известное старым добрым рвением синих воротничков, нашим энтузиазмом ко всему, от нашей футбольной команды (STEELERS !!) до нашего пива (Iron City) и наших сладостей (Primanti’s, брат!). Таким образом, мы, естественно, склонны поощрять напыщенные публичные демонстрации нашей привязанности — в данном случае, отмечая себя!
Место, известное старым добрым рвением синих воротничков, нашим энтузиазмом ко всему, от нашей футбольной команды (STEELERS !!) до нашего пива (Iron City) и наших сладостей (Primanti’s, брат!). Таким образом, мы, естественно, склонны поощрять напыщенные публичные демонстрации нашей привязанности — в данном случае, отмечая себя!
Я смотрел рекордный фейерверк в Питтсбурге 250 с прекрасной точки на Северном берегу, поддерживая свой город с балкона McFadden’s вместе с огромной группой каучсерферов, приехавших в Питтсбург на региональные выходные.Все время, пока я восхищался яркими всплесками и грохочущими взрывами — продолжительностью тридцать минут! — в моей голове постоянно мелькала мысль: «Что именно В этом массивном облаке дыма, клубящемся через реку?»
«Состав фейерверков», страница, составленная Ремой Гондхиа из Имперского колледжа в Лондоне, дает вам фактическое изложение состава фейерверков. Химический состав фейерверка, каким бы гениальным он ни был для демонстрации наших захватывающих визуальных удовольствий, дает некоторые тревожные названия — химические вещества с длинными отчетами исследовательских институтов, указывающими на их угрозу для живых систем. Прочтите несколько тревожных примеров.
Хлораты и перхлораты . Используемые в фейерверках в качестве окислителей, они считаются опасными для здоровья человека в виде пыли Энциклопедией гигиены труда, в которой говорится, что их эффекты включают «боль в горле… головокружение… они вызывают раздражение кожи, глаз и слизистых оболочек… они может вызвать гемолитическую анемию … и повреждения печени и почек ».
Сера . Реагирует с кислородом во время взрыва фейерверка с образованием диоксида серы (SO2).Находясь в воздухе, диоксид серы опасен для здоровья человека и может привести к серьезным неврологическим и мозговым повреждениям, повреждению сосудов и повреждению внутренних ферментов у живых существ.
Неестественное Стронций Химические связи (используемые для придания красного цвета фейерверку) могут быть опасны для здоровья человека, особенно в водорастворимой форме. Они могут загрязнять водные пути и пищу, а также воздух.
Хотя большинство компонентов фейерверков могут быть безвредными до возгорания, следует учитывать их эффекты при беспорядочном распределении на небольшой площади в газообразной форме после взрыва.Как будто Питтсбург недостаточно загрязнен твердыми частицами! Пища для размышлений в следующий раз, когда вы будете устраивать публичный фейерверк.
Как граждане страны, которая традиционно трепещет от фейерверков, но как озабоченные люди, которые хотят лучшего и безопасного будущего для следующих поколений, разве мы не могли бы протестовать против фейерверков из-за их неощутимой опасности? Есть ли какие-то альтернативы, которые мы могли бы предложить, столь же захватывающие, но не столь опасные? Если это так, то празднование в обществе наследия и традиций не обязательно должно быть пощечиной окружающей среде, а наоборот, может понравиться всем.Даже… по рыбе.
, фото: Neurovelho под лицензией GNU Free Documentation License ; Раймонд Спеккинг под лицензией свободной документации GNU
Если вам понравилась эта статья, ознакомьтесь с ее предшественником: Часть первая: Экологические отчеты Питтсбурга и Любовь к фейерверкам «Дымного города»
Рэнди Бэнгс, музыка и гуманитарные науки
Когда Рэнди Бэнгс учился в Бельгии у Флора Петерса, известного композитора, склонного к инновациям, он повлиял не только на ее подход к игре на клавиатуре, но и на обучение будущих учеников.
«Я узнал, что Бетховен нарушил все правила композиции, — говорит Бангс, — и что он верил, что все люди должны жить в мире и согласии».
И то, и другое играет важную роль в философии обучения Бангса. Будь то фортепиано или введение в курс искусств, которые она преподает в Macomb, она рассматривает каждого ученика как личность, а каждый класс — как новое приключение, заслуживающее свежих идей.
«У меня был один профессор в Wayne State, который читал лекции с тех же пожелтевших заметок, которые он использовал в течение многих лет», — рассказывает Бангс, преподававший в Macomb в течение 12 лет.«Но я всегда спрашиваю себя, как я могу изменить свой подход, чтобы привлечь моих учеников? Как мне сделать так, чтобы они были в восторге от посещения занятий? »
Для Bangs ответ отчасти заключается в использовании технологий. Введение в курс искусств, который она преподает, представляет собой гибрид, за разработку которого она считает Стюарта Скотта, коллегу-профессора гуманитарных наук. Предмет легко поддается визуальным подсказкам, которые наиболее эффективны для привлечения студентов, привыкших к временным изображениям в социальных сетях.
Предмет легко поддается визуальным подсказкам, которые наиболее эффективны для привлечения студентов, привыкших к временным изображениям в социальных сетях.
«Они наглядные ученики», — предлагает Челка.«Мы можем говорить о короткой продолжительности концентрации внимания или можем работать с этой продолжительностью внимания и, возможно, заинтересовать их тем, что они изучают».
С ее учениками по фортепиано большая задача — помочь новичкам преодолеть свои страхи.
«Они начинают осторожничать и нервничать и говорят мне:« Я хочу научиться играть на фортепиано », — рассказывает Бангс. «Выражение их лиц, когда они играют свои первые несколько нот, очень волнующее. Фортепиано как групповое занятие может доставлять массу удовольствия ».
Bangs, однако, начался с частных уроков после того, как однажды, вернувшись из школы, обнаружил в гостиной пианино и мать, объяснившую отцу, что их маленькая дочь собирается научиться играть.Оказалось, Бангз это понравилось, и, как и ее герой Бетховен, она научилась играть на органе. Она получила степень бакалавра музыки в Государственном университете Уэйна и степень магистра и докторскую степень в области музыкального исполнительства и музыкального образования соответственно в Университете Майами.
Она получила степень бакалавра музыки в Государственном университете Уэйна и степень магистра и докторскую степень в области музыкального исполнительства и музыкального образования соответственно в Университете Майами.
«Профессор Питерс отвечает за то, что я поеду в Майами, — объясняет Бангс, — чтобы учиться у одного из его бывших студентов».
Бэнгс оставалась во Флориде более двух десятилетий, преподавая орган и фортепиано в государственных школах округа Дейд, прежде чем вернуться в Мичиган, когда ее отец заболел.Проведя лето в Мексике в подростковом возрасте, путешествуя по Китаю и живя в Европе, она побывала во многих местах. Вена, где жили и похоронены Бетховен и Моцарт, — ее любимая страна. Но именно в Macomb она нашла свой особый вид гармонии.
«Приятно быть крошечной частью преобразования моих учеников, — говорит Бангс. «Что может быть лучше, чем помочь кому-то другому реализовать свои мечты?»
Amazon.co.jp: [4 цвета] парик с челкой, челка, в комплекте сбоку, прозрачная челка, зажим, натуральная термостойкость, парикмахерские, парик, наращивание, человеческие волосы, с напускным лицом, милый, точечный парик, частично Парик, Shanghai Lifestyle Shop
Описание продукта:
Пушистые, легкие и удобные в носке. Доступен в 4 цветах. Боковая челка Полностью посаженная вручную Боковая челка Парик, зажим для легкой установки. Его легко надеть, поэтому парики с челкой могут понравиться даже новичкам.
Доступен в 4 цветах. Боковая челка Полностью посаженная вручную Боковая челка Парик, зажим для легкой установки. Его легко надеть, поэтому парики с челкой могут понравиться даже новичкам.
Легко носить частичный парик, просто защелкните его поверх отдельной челки. Даже если вы не хотите стричь челку, вы можете превратить ее в девушку с челкой.
Простой и неповторимый корейский стиль, способный изменить имидж и популярный среди женщин. Вы можете использовать его свободно. Термостойкий, поэтому его можно свернуть или прямо. Цвета сделать нельзя.
Со стороной, которая хорошо сочетается с хвостиками и пучками, можно ожидать меньшего лица.
Если он слишком длинный или слишком толстый, вы можете отрезать его самостоятельно.
Натуральный парик выглядит так, как будто он не подходит вашим собственным волосам. Волосы мягкие и не имеют характерного блеска парика.
Он имеет естественный блеск, мягкий на ощупь, гладкий и гладкий на ощупь. Это очень натуральные волосы.
Комплект поставки: парик челки, 1 зажим в одно касание, прост в установке. [Доступна химическая завивка и расцветка] Нельзя использовать.Примечание. Если вы хотите другой цвет при заказе набора из 2 штук, укажите номер заказа и свяжитесь с нами. ] Примечания по использованию:
[Доступна химическая завивка и расцветка] Нельзя использовать.Примечание. Если вы хотите другой цвет при заказе набора из 2 штук, укажите номер заказа и свяжитесь с нами. ] Примечания по использованию:
Благодарим вас за выбор этого продукта.
Несмотря на то, что мы стремимся сделать наши изображения максимально приближенными к реальным товарам, цвет может отличаться в зависимости от монитора вашего компьютера, настроек, освещения в вашей комнате, солнечного света и т. Д. Пожалуйста, воздержитесь от участия в торгах. Спасибо за Ваше понимание.
Мы проверяем и отправляем этот продукт, но поскольку это зарубежный продукт, качество ткани, техника шитья и детали производства не идеальны.Кроме того, обратите внимание, что могут быть случаи, когда нити могут ослабнуть и т. Д.
Цвета могут блекнуть при стирке, поэтому стирайте вручную отдельно.
Это явление заключается в том, что новый парик всегда был вызван зашивкой волос во время производства парика. После удаления облысения вы вряд ли заметите, что выпадение волос.
В процессе производства париков большинство деталей выполняется вручную, поэтому отдельные изделия могут отличаться. (Длина и стрижка щетины, условия расчесывания, завитки, слабое шитье и т.д.)
Размеры измеряются в соответствии с действительными размерами, поэтому возможны незначительные отклонения. Спасибо за Ваше понимание.
Имейте в виду, что в зависимости от даты производства продукта дизайн или цвет самого продукта могут измениться.
Другие аксессуары, отличные от содержимого продукта, не включены. Спасибо за Ваше понимание.
Доставка: Мы отправим товар в течение 3-5 рабочих дней после получения оплаты.
Срок поставки: это займет от 6 до 12 рабочих дней после получения оплаты.Пожалуйста, воздержитесь от заказа, если он вам нужен срочно.
О заказе:
Пожалуйста, воздержитесь от отмены, так как товары будут заказаны после размещения вашего заказа. Кроме того, если у производителя закончится товар, вы не сможете отправить его даже после того, как разместите заказ.
Здоровые ли энергетические напитки Bang?
Энергетические напитки редко бывают хорошим выбором.
Многие шокируют ваш организм колоссальным количеством кофеина и сахара, пытаясь повысить бдительность, но этот внезапный всплеск энергии обычно сопровождается тяжелым сбоем, из-за которого вы чувствуете себя хуже, чем раньше.Большинство энергетических напитков по питательности эквивалентны газировке, и вы достаточно умны, чтобы знать, что банка кока-колы не приносит никакой пользы вашему здоровью.
Но энергетический напиток под названием BANG быстро набирает популярность благодаря заявлениям и фактам питания, которые, казалось бы, резко контрастируют с традиционными вариантами, такими как Monster или Rockstar. Учитывая восторженные отзывы в Интернете, действительно ли BANG — это будущее энергетических напитков?
Давайте подробнее рассмотрим, действительно ли энергетические напитки BANG настолько полезны, как некоторые могут вас представить.
Энергетические напитки BANG бывают разных вкусов, но похоже, что каждый из них имеет идентичные (или почти идентичные) характеристики питания. Одна банка BANG на 16 унций содержит:
- 0 калорий
- 0 грамм жира
- 0 мг холестерина
- 40 мг натрия
- 85 мг калия
- 0 грамм углеводов
- 0 захватов волокна
- 0 грамм сахара
- 0 грамм белка
- 50% дневной нормы витамина C
- 25% дневной нормы ниацина
- 25% суточной нормы витамина B6
- 25% суточной нормы витамина B12
- 2% суточной нормы магния
По сравнению с банкой Rockstar объемом 16 унций, в которой содержится 260 калорий и 62 грамма сахара, пищевые показатели выглядят значительно лучше.Часто употребление напитков с высоким содержанием сахара — серьезная опасность для вашего здоровья. Это не только может привести к плохому составу тела, но и значительно увеличивает риск нескольких неблагоприятных последствий для здоровья. Регулярное употребление напитков с высоким содержанием добавленного сахара связано с повышенным риском рака, сердечных заболеваний и диабета 2 типа. Американская кардиологическая ассоциация рекомендует ограничивать 24 грамма в день для женщин и 36 граммов в день для мужчин. Каждый грамм сахара также содержит 4 калории, поэтому большое количество сахара может быстро привести к резкому увеличению общего количества калорий (например, 95% калорий в вышеупомянутой банке Rockstar на 16 унций поступает из сахара).
Регулярное употребление напитков с высоким содержанием добавленного сахара связано с повышенным риском рака, сердечных заболеваний и диабета 2 типа. Американская кардиологическая ассоциация рекомендует ограничивать 24 грамма в день для женщин и 36 граммов в день для мужчин. Каждый грамм сахара также содержит 4 калории, поэтому большое количество сахара может быстро привести к резкому увеличению общего количества калорий (например, 95% калорий в вышеупомянутой банке Rockstar на 16 унций поступает из сахара).
Но BANG по-прежнему несёт много сладости, несмотря на отсутствие сахара. Как? Посмотрим на ингредиенты:
Уф — это много слов, которые большинство людей не узнает.
Сукралоза — это секрет того, почему BANG может иметь такой приятный вкус, несмотря на то, что он не содержит ни грамма сахара. Сукралоза — это обычный искусственный подсластитель, который в 320-1000 раз слаще столового сахара. Splenda — один из распространенных подсластителей на основе сукралозы. Healthline заключает, что сукралозу «вероятно можно использовать в умеренных количествах», если ваше тело хорошо с ней справляется, и она в целом признана безопасной FDA.Однако это может вызвать проблемы со здоровьем кишечника и, как и большинство искусственных подсластителей, вероятно, не поможет вам снизить общее потребление калорий по большому счету. Когда мы потребляем что-нибудь сладкое, это сигнализирует нашему телу о том, что нужно ожидать поступления калорий. Когда эти калории не поступают, как в случае с газированными или энергетическими напитками с нулевым содержанием калорий, мы часто в конечном итоге потребляем больше калорий в других местах, чтобы восполнить то, что «не хватает».
Healthline заключает, что сукралозу «вероятно можно использовать в умеренных количествах», если ваше тело хорошо с ней справляется, и она в целом признана безопасной FDA.Однако это может вызвать проблемы со здоровьем кишечника и, как и большинство искусственных подсластителей, вероятно, не поможет вам снизить общее потребление калорий по большому счету. Когда мы потребляем что-нибудь сладкое, это сигнализирует нашему телу о том, что нужно ожидать поступления калорий. Когда эти калории не поступают, как в случае с газированными или энергетическими напитками с нулевым содержанием калорий, мы часто в конечном итоге потребляем больше калорий в других местах, чтобы восполнить то, что «не хватает».
СВЯЗАННЫЙ: Почему низкокалорийные диетические газированные напитки все еще могут быть плохими для вас
Полное отсутствие белка и клетчатки не является нетипичным для энергетических напитков, но это означает, что не стоит ожидать, что BANG насытят. Достаточное количество витаминов — это хорошо, но если вы не придерживаетесь ужасной диеты, скорее всего, у вас нет дефицита витаминов группы B или витамина C, а потребление большего количества витаминов, чем рекомендованная дневная норма, дает небольшую пользу. Итак, если говорить о чистом питании, у вас есть искусственно подслащенный напиток с нулевой калорийностью, без белка, клетчатки и некоторых витаминов. Но в случае с такими напитками пищевая ценность редко раскрывает всю картину.
Достаточное количество витаминов — это хорошо, но если вы не придерживаетесь ужасной диеты, скорее всего, у вас нет дефицита витаминов группы B или витамина C, а потребление большего количества витаминов, чем рекомендованная дневная норма, дает небольшую пользу. Итак, если говорить о чистом питании, у вас есть искусственно подслащенный напиток с нулевой калорийностью, без белка, клетчатки и некоторых витаминов. Но в случае с такими напитками пищевая ценность редко раскрывает всю картину.
Если вы говорите о BANG, вы должны изучить то, что компания называет своим «мощным топливом для мозга и тела»: коктейль из кофеина, CoQ10, SUPER CREATINE (то, что компания называет своим запатентованным созданием Creatyl-L-Leucine ) и BCAA.Помимо кофеина, мы не можем точно определить, сколько из этих ингредиентов содержится в каждой банке BANG. Этого нет ни на этикетке, ни на официальном сайте компании. Не идеально!
Таким образом, хотя BCAA (аминокислоты с разветвленной цепью), креатин и CoQ10 (коэнзим 10) могут дать некоторую пользу, особенно для людей с дефицитом в рационе, мы не можем проанализировать, как они влияют на профиль питания BANG. Что еще больше усложняет ситуацию, компания VPX Sports, стоящая за этим напитком, в настоящее время подает в суд на основании утверждений, что их «SUPER CREATINE» на самом деле вовсе не креатин.
Что еще больше усложняет ситуацию, компания VPX Sports, стоящая за этим напитком, в настоящее время подает в суд на основании утверждений, что их «SUPER CREATINE» на самом деле вовсе не креатин.
Теперь, вероятно, самое время также сказать вам, что каждая банка BANG украшена таким количеством предупреждений, что можно подумать, что это боевая ручная граната. К ним относятся:
- Не предназначено для лиц младше 18 лет
- Не используйте этот продукт, если вы беременны или кормите грудью
- Не употребляйте этот продукт, если вы принимаете какие-либо лекарства по рецепту и / или страдаете каким-либо заболеванием.
- Этот продукт содержит кофеин и не должен использоваться с другими продуктами, содержащими кофеин
- Этот продукт предназначен только для здоровых людей
В настоящее время напиток окружен множеством красных флажков и серых зон.Но мы точно знаем, что банка BANG на 16 унций содержит ошеломляющие 300 мг кофеина. Средняя чашка заваренного кофе на 8 унций содержит 95 мг, а банка Red Bull на 12 унций — 111 мг. Как ни крути, это невероятное количество кофеина в одной порции. Но не слишком ли много?
Средняя чашка заваренного кофе на 8 унций содержит 95 мг, а банка Red Bull на 12 унций — 111 мг. Как ни крути, это невероятное количество кофеина в одной порции. Но не слишком ли много?
В недавнем обзоре, опубликованном в журнале Food and Chemical Toxicology , были рассмотрены 700 исследований, чтобы определить, что можно считать «безопасным» уровнем потребления кофеина. Их результаты показали, что следующие количества ежедневного потребления кофеина безопасны, поскольку они не связаны с «явными побочными эффектами»:
- 400 мг для здоровых взрослых
- 300мг для беременных
- 2.5 мг на кг массы тела для детей и подростков
Хотя невозможно точно знать, как каждый будет реагировать на кофеин, ограничение в 400 мг в день обычно считается безопасным для подавляющего большинства здоровых людей. Но эти слова в день важны. Выпив банку BANG, вы можете снизить уровень кофеина на 300 мг за считанные минуты, что может быть слишком много, слишком быстро для людей, которые не привыкли к такой дозе. В предупреждении на банках BANG подробно говорится, что «слишком много кофеина может вызвать нервозность, раздражительность, бессонницу и, иногда, учащенное сердцебиение.«
В предупреждении на банках BANG подробно говорится, что «слишком много кофеина может вызвать нервозность, раздражительность, бессонницу и, иногда, учащенное сердцебиение.«
Но этот сенокос с кофеином — та же самая причина, по которой многие спортивные крысы любят его. Кофеин может быть чрезвычайно привлекательным веществом для тех, кто занимается интенсивной физической активностью. Исследования показали, что умеренное количество кофеина может помочь вам отсрочить истощение, сжечь больше жира, уменьшить боль, связанную с упражнениями, и помочь лучше восстановить уровень гликогена в мышцах. Обзор 2016 года, опубликованный в журнале Neuroscience & Biobehavioral Reviews , показал, что дозы кофеина более 200 мг были «эргогенными для всего спектра модальностей упражнений» в изученных исследованиях.Эргогенность определяется как «улучшение физической работоспособности».
«Кофеин, изученный в его изолированной форме, оказался одним из самых испытанных и действенных веществ, повышающих производительность за все время. Он может просто помочь вам получить дополнительный толчок, необходимый во время спортивного выступления», — Райан Эндрюс, Об этом STACK сообщили RD и тренер по питанию в Precision Nutrition.
Он может просто помочь вам получить дополнительный толчок, необходимый во время спортивного выступления», — Райан Эндрюс, Об этом STACK сообщили RD и тренер по питанию в Precision Nutrition.
Таким образом, значительная доза кофеина, при условии, что вы хорошо ее переносите, определенно может стать серьезным стимулом для многих видов физической активности.В дополнение к «повышению», вызванному BANG, многие интернет-обозреватели положительно отзываются о пищевой ценности напитка, его вкусе и отсутствии срыва. Напиток содержит 0 калорий и 0 углеводов, что является очень привлекательным фактором для многих потребителей, особенно для тех, кто придерживается низкоуглеводной или кетогенной диеты. Потребление значительного количества сахара приводит к быстрому скачку уровня сахара в крови, а затем к его быстрому падению, что может привести к чувству усталости, вялости и раздражительности. Однако искусственный подсластитель, используемый в BANG, не оказывает кратковременного воздействия на уровень сахара в крови. Исключая сахар, BANG предотвращает падение сахара, присущее многим другим энергетическим напиткам.
Исключая сахар, BANG предотвращает падение сахара, присущее многим другим энергетическим напиткам.
BANG содержит огромное количество кофеина, без сахара, углеводов и калорий. Для людей, которым надоели традиционные энергетические напитки, но которые хотят получить от них заряд энергии, этот пакет может быть очень привлекательным. BCAA, CoQ10 и SUPER CREATINE могут немного сдвинуть иглу, но когда вы не знаете, сколько содержится в каждой банке, они выглядят скорее как броские модные словечки, чем как важные компоненты успеха напитка.
В конечном счете, мы не можем рекомендовать сделать энергетические напитки BANG регулярной частью вашего распорядка дня. Их основные пищевые характеристики могут выглядеть значительно лучше, чем у большинства энергетических напитков, но есть также ряд серьезных красных флажков, окружающих продукт. Мы полагаем, что вы могли бы поступить еще хуже, если бы вам абсолютно необходимо было выпить энергетический напиток, но для большинства людей большой кофе может обеспечить повышение уровня кофеина без сахара, наряду со многими полезными естественными питательными веществами, без беспокойства.
Фотография предоставлена: GNC
ПОДРОБНЕЕ:
Профессиональное чтение: Молли Бэнг. Представьте это
Банг, Молли. Представьте это: Как работают изображения, исправленное и расширенное 25 -е издание , юбилейное. Хроника, 1991/2016. 134п. 28,99 долл. США, 978-1-4521-3515-1.
Вы когда-нибудь задумывались, почему что-то на иллюстрации заставляет вас чувствовать себя напряженным или спокойным? Ответы на эти и подобные вопросы даны в пересмотренном издании книги Bang’s Picture This: Perception and Composition (Bullfinch, 1991), посвященном 25-летию -й годовщины . У меня было оригинальное издание, я сравнил его с этой новой версией и был очень рад, что эта новая презентация оказалась такой эффективной.
Используя вырезки из бумаги черного, светло-фиолетового, белого и красного цветов, Банг демонстрирует многие концепции, относящиеся к композиции изображений, особенно двенадцать принципов, которые она излагает. К ним относится принцип, согласно которому плоские горизонтальные формы дают нам ощущение спокойствия, а вертикальные — захватывающие. Диагонали подразумевают напряжение, светлый фон кажется безопасным, а темный — страхом. Каждый принцип связан как минимум с одной иллюстрацией, изображающей концепцию.
К ним относится принцип, согласно которому плоские горизонтальные формы дают нам ощущение спокойствия, а вертикальные — захватывающие. Диагонали подразумевают напряжение, светлый фон кажется безопасным, а темный — страхом. Каждый принцип связан как минимум с одной иллюстрацией, изображающей концепцию.
Это новое издание больше по размеру, но примерно такое же количество страниц, и оно включает новый раздел «От намерения к исполнению», в котором используются примеры из ее собственных иллюстрированных книг.Используя несколько иллюстраций из своей книги «Колдекотт Хонор» , Когда Софи злится — действительно, действительно злится, (Blue Sky Press, 1999), Банг описывает элементы каждой картинки, используемые для вызова эмоции. Например, чтобы вызвать у Софи чувство ярости, произведение искусства содержит много красного, а тень Софи намного больше, чем она, чтобы изобразить ее обостренные эмоции.
Хотя эта книга не охватывает художественные медиа или стили, это ключевой ресурс для библиотекарей, которые рецензируют иллюстрированные книги. Большая часть текста такая же, как и в оригинале, но новая информация и улучшенный дизайн книги делают ее гораздо более эффективным руководством о том, как наше визуальное восприятие и эмоциональная реакция на изображения основываются на этих принципах дизайна. Настоятельно рекомендуется для развития персонала.
Большая часть текста такая же, как и в оригинале, но новая информация и улучшенный дизайн книги делают ее гораздо более эффективным руководством о том, как наше визуальное восприятие и эмоциональная реакция на изображения основываются на этих принципах дизайна. Настоятельно рекомендуется для развития персонала.
Пенни Пек, SJSU iSchool
Свидетельства Большого взрыва
Астрономы считают, что Вселенная началась с Большого взрыва. Как и вся наука, это основано на свидетельствах ; так каковы доказательства теории Большого взрыва?
Спиральная галактика — M51Авторы и права: NSO
1.Красное смещение галактик
Красное смещение далеких галактик означает, что Вселенная, вероятно, расширяется. Если мы затем вернемся достаточно далеко во времени, все должно было быть сплющено в крошечную точку. Быстрое извержение этой крошечной точки было Большим взрывом.
Космический микроволновый фонПредоставлено: NASA / WMAP Team
2.
 Микроволновый фон
Микроволновый фонВ самом начале своей истории вся Вселенная была очень горячей.Расширяясь, это тепло оставляло за собой «свечение», заполняющее всю Вселенную. Теория Большого взрыва не только предсказывает, что это свечение должно существовать, но и что оно должно быть видимым в виде микроволн — части электромагнитного спектра.
Это космический микроволновый фон, который был точно измерен орбитальными детекторами и является очень хорошим доказательством правильности теории Большого взрыва.
Солнце — довольно новая звезда.Авторы и права: NASA
3.Смесь элементов
По мере расширения и охлаждения Вселенной были созданы некоторые из элементов , которые мы видим сегодня. Теория Большого взрыва предсказывает, сколько каждого элемента должно было быть создано в ранней Вселенной, и то, что мы видим в очень далеких галактиках и старых звездах, совершенно верно.
Вы не можете искать это свидетельство в новых звездах, таких как Солнце, потому что они содержат элементы, которые были созданы в предыдущих поколениях звезд. Таким образом, состав новых звезд будет сильно отличаться от состава звезд, существовавших 7 миллиардов лет назад, вскоре после Большого взрыва.
Таким образом, состав новых звезд будет сильно отличаться от состава звезд, существовавших 7 миллиардов лет назад, вскоре после Большого взрыва.
4. Взгляд в прошлое
Основная альтернатива теории Большого взрыва Вселенной называется теорией устойчивого состояния . Согласно этой теории, Вселенная не сильно меняется со временем.
Помните, что, поскольку свету требуется много времени, чтобы пройти через Вселенную, когда мы смотрим на очень далекие галактики, мы также смотрим на назад во времени .
Из этого мы видим, что галактики давным-давно сильно отличались от сегодняшних, показывая, что Вселенная изменилась.Это лучше согласуется с теорией Большого взрыва, чем с теорией устойчивого состояния.
.